
探索bit级别sparsity的存内计算核——JSSC2023.1
该篇文章由电子科大与北大联合发表。摘要截图如下:
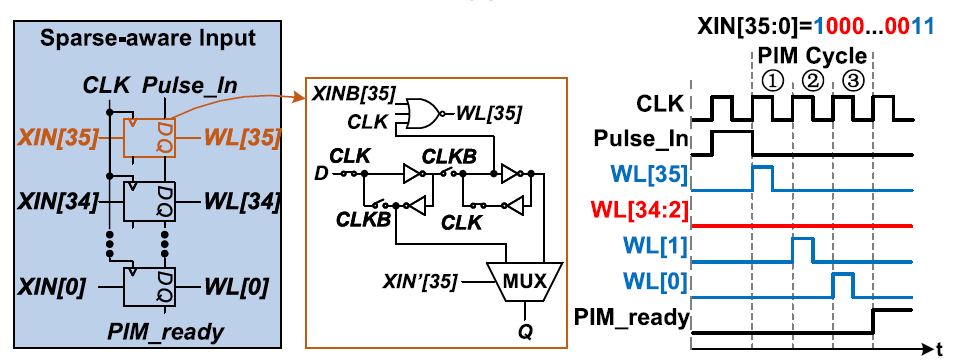
这个加速器的工作原理是bit-serial的存内计算(CIM)架构,将input activation中同一个bit-level的36个bit接在CIM模块的字线(WL)上,接下来每一个clock cycle激活一条WL。如果当前的WL为1,位线(BL)上读出RRAM中存储的weight bit。在每一条BL的下方用一个counter记录BL输出脉冲的个数。BL输出一个脉冲,代表当前input activation与weight的bit相乘等于”1”。而下面的counter就用于这些”1”的累加,最后通过shifter移位器左移相应的bit level即可。尽管这种架构能够节省ADC/DAC的面积和功耗,但也带来了计算密度低的缺点,它的macro大小为36$\times$128,平均一个clock cycle只能计算128个1bit乘法。根据该文章后边的数据,在22nm工艺下这样的cell大小为443.8$\mu m^2$。对于100MHz的工作频率而言,一个macr ...

