JSSC 2023.2 Design and Implementation of a Hybrid, ADC/DAC-Free, Input-Sparsity-Aware, Precision Reconfigurable RRAM Processing-in-Memory Chip
探索bit级别sparsity的存内计算核——JSSC2023.1

该篇文章由电子科大与北大联合发表。摘要截图如下:

这个加速器的工作原理是bit-serial的存内计算(CIM)架构,将input activation中同一个bit-level的36个bit接在CIM模块的字线(WL)上,接下来每一个clock cycle激活一条WL。如果当前的WL为1,位线(BL)上读出RRAM中存储的weight bit。在每一条BL的下方用一个counter记录BL输出脉冲的个数。BL输出一个脉冲,代表当前input activation与weight的bit相乘等于”1”。而下面的counter就用于这些”1”的累加,最后通过shifter移位器左移相应的bit level即可。尽管这种架构能够节省ADC/DAC的面积和功耗,但也带来了计算密度低的缺点,它的macro大小为36$\times$128,平均一个clock cycle只能计算128个1bit乘法。根据该文章后边的数据,在22nm工艺下这样的cell大小为443.8$\mu m^2$。对于100MHz的工作频率而言,一个macro最高的throughput能达到0.4GOPs。该加速器共有128个这样的macro,可以计算其理论上最高吞吐量为204.8GOPs(I4W4)。
可见这样的架构如果不利用好它串行输入input activation的特性,在吞吐量上是十分吃亏的。因为,该加速器除了对每一层的activation都量化到不同的bit精度之外(称为dynamic precision),还设计了用于处理bit级别sparsity的模块。
这个结构对接入WL的input sparsity进行过滤,当WL上为0时,MUX将前一级的脉冲接到后一级去,从而跳过了这条WL上的input sparsity,可以说是非常巧妙了。
该芯片制程为180nm,总面积为$35.26nm^2$。其中大多数电路为数字电路。从它的power breakdown图来看,它的大多数功耗由ripple counter产生(56.5%)。文中有对ripple counter的面积消耗做一个讨论。在180nm中,10-b的ripple counter所占面积为$ 70 \times 14 \mu m $, 一个D触发器面积为$ 7 \times 14 \mu m $, 而一个工作在100MHz下的10b SAR ADC面积为$ 256 \times 195 \mu m $,因而文中说使用ripple counter在面积上是很划算的。但该芯片需要使用$ 256 \times 128 = 32K $个这样的counter,成为了该芯片counter上的功耗与面积消耗如此之大的原因。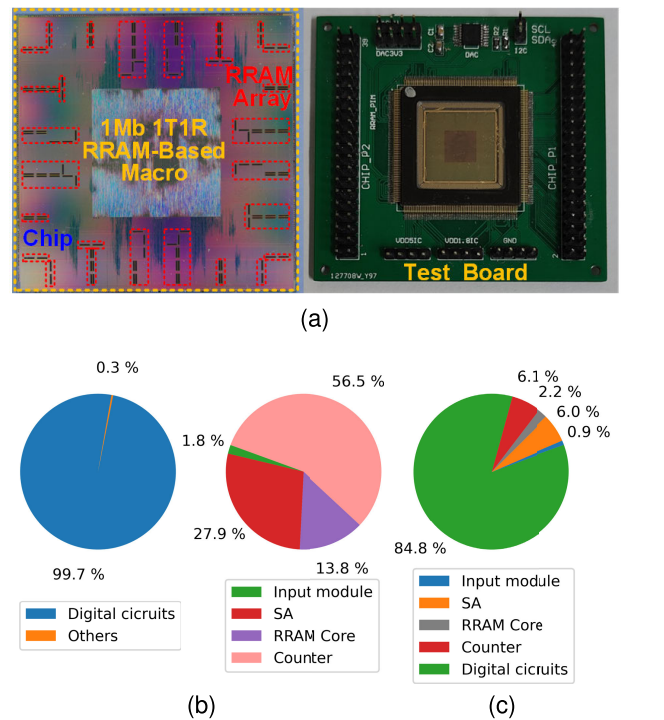
为什么这个CIM加速器不需要ADC和DAC?
这是因为input是一个一个脉冲输入的,且CIM单元采用了数字计算的模块,利用一个counter将结果累加起来,所以输出也是数字信号,由于不存在模拟域的计算,所以不需要ADC和DAC。