
数据和模型设计层面怎样让Transformer运行地更加高效——ACL2023
数据和模型设计层面怎样让Transformer更加高效——ACL2023
去年在ACL2023会议上发表的一篇综述性文章,系统地介绍了近年来可以应用在自然语言处理(NLP)任务中提高计算效率的方法。文章名,作者以及单位贴出如下:
将这些方法整理为一个工具包,可以总结成下图: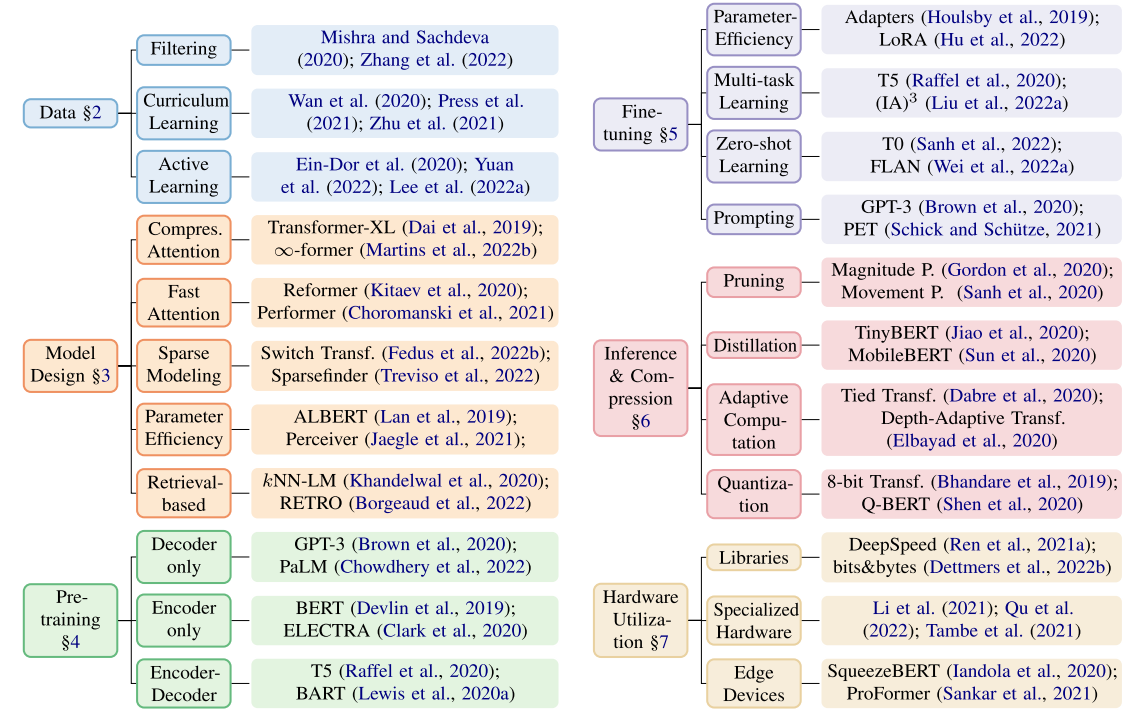
数据(data)层面:
data filtering,目标是减少无效的训练样本,比如减少样本的重复性。
active learning, 和data filtering不同,主动学习动态地更新训练集的样本,其流程如下: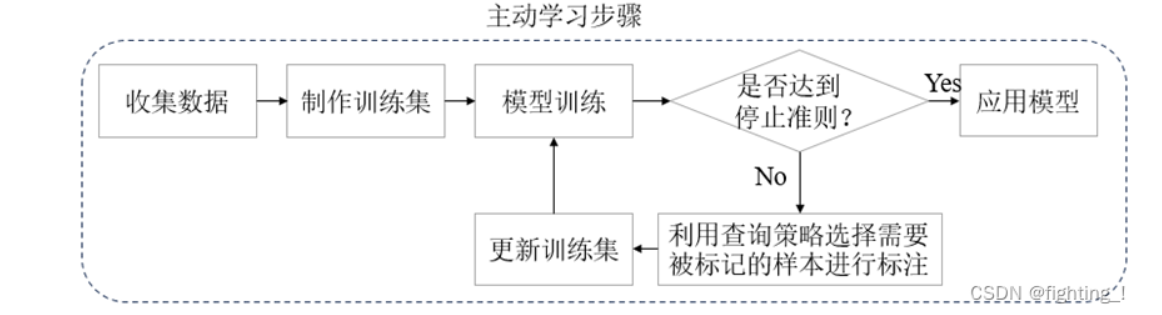
Curriculum Learning,通过改变训练集样本的顺序来提高计算效率,其并不改变训练集的大小。
模型设计(Model design)层面:
Compress Attention, Transforer-XL引入了循环机制和相对位置编码,使其inference比vanillar Transformer快300~1800倍。另一个案例是$ \infty $-former, 其目的是为了让系统能够hold住任意序列长度的attention。由对attention map (过Normalized Softmax后的$QK^T$矩阵)的每一行都可以视为一个离散概率质量函数,首先可以把它转化为一个连续的概率密度函数,这也被称作continuous attention。之后用N个基函数来表示这个连续概率密度函数。由于N远远小于sequence length并且是固定的,所以其能在有限的内存中处理无限长度的序列attention,代价是损失了长程记忆的resolution。实验证明该方法在处理长序列时(sequence length>8000)拥有比Transformer-XL更好的表现。
Fast Attention, 一种是sparse Attention, 即通过一个需要设定好的attention mask来降低attention map的计算量,代表是Reformer。另一种是通过主成分分析(PCA)的方法,计算attention map的low rank部分,代表是Performer。当然还有由Tri. Dao博士提出的Flash Attention方法,通过设计了一种新的IO-aware的attention计算模式,从memory hierarchy的角度优化了attention的计算效率。
Sparse modeling, 这个方法包含了专家混合Mixture of Expert (MoE)的思想,每次inference只选择性地经过模型中的一小部分,而不会跑完整个网络,英文中将整个概念成为sparsely-activated model。其代表为Switch Transformer,它将Transformer中self-attention后的全连接层(FFN)替换为了一个称作”sparse Switch FFN”的层,如下图所示:

另一个方法是SparseFinder,发表在2022年的论文“Predicting Attention Sparsity in Transformers”上,和Fast attention中提到的预先设定好的attention mask不同,SparseFinder通过知识蒸馏训练一个student model来预测这个attention mask。其能在WikiText-103模型上取得98.04%的sparsity ratio(相当于inference time提升了近51倍)。
Parameter efficiency, 这个方法注重降低模型参数量以节省计算与内存开销。典型方法如ALBERT,通过embedding参数分解和层间参数共享大大减少了参数量。ALBERT-base模型只有12M的参数量,却能在SQuAD2.0任务中取得和BERT-base相似的表现(80.0:80.4)。所谓embedding参数分解的意思是把embedding层的输出矩阵(大小为$V \times H$, $V$为sequence length,$E$为hidden size)通过一个linear层转化为$ V \times E $,在计算完成后再转化回来。则理论上,新的参数量由$ V \times H $变为了$V \times E + E \times H$,当$E$远小于$H$时,能极大地降低参数量。
Retrieval-based, retrieve指的是从大量数据中检索信息以增强语言模型的性能。以RETRO模型为例,其可以从包含20000亿个token的数据库中检索出与当前token相似的token用于预测新的token。相较于GPT3,其使用了25倍小的模型参数量,却取得了相近的表现。
