处理帧间残差——ISSCC2020 14.2
文章名与作者单位列出如下,来自清华大学刘永攀组。
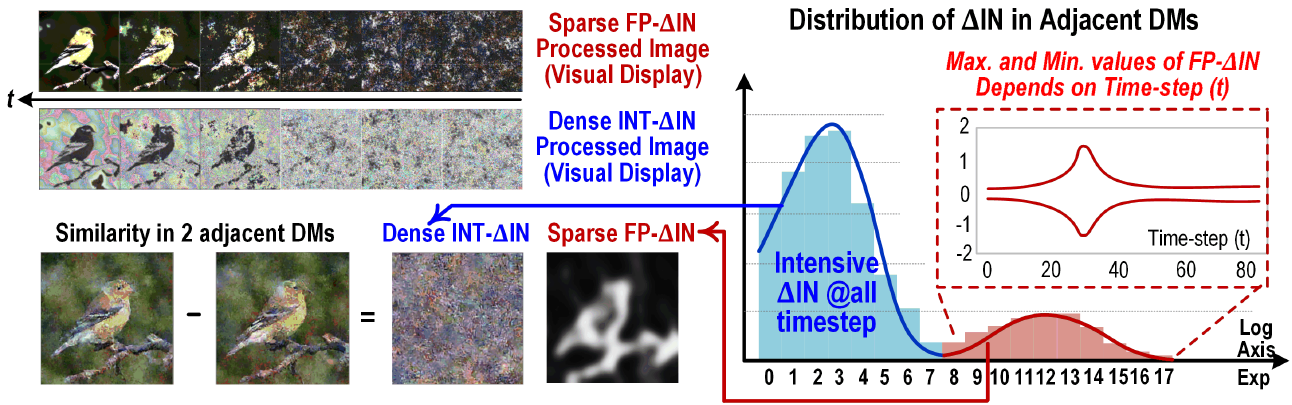
从名称可知,这个work主要目标是部署一个能够感知两次activation输入相似性的CNN神经网络。由于在视频处理中,相邻的两帧之间差别很小。把相邻的两帧作差,得到的feature map包含大量的sparsity (为0的值)。

软件层面,控制帧重用的flow的工作模式如下: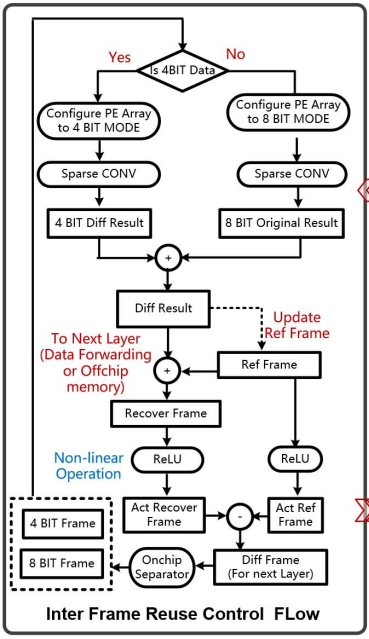
对神经网络的每一层,第一帧作为一个完整的图像进行处理,但接下来的帧仅仅处理与上一帧作差的结果,我将其称为帧间残差(difference frame)。由于帧间相似性,这个difference frame可以被量化为4b低精度矩阵与8b高精度稀疏矩阵的结合,之后可对两部分矩阵可以进行分治操作。由于ReLU操作的处理目标为原始图像,神经网络中除ReLU以外的所有操作都由difference frame作input activation。在进行ReLU之前,difference frame将会还原当前帧的原始图像(Recover frame),上图中左路的分支为当前帧的原始图像,而右路分支为前一帧。两者都进行ReLU之后,再重新生成difference frame用于下一层。
这样做的效果是显著的,文中这句话明确地描述了inter-frame reuse能够带来的好处。

本文提出的第二个feature是处理difference frame计算时的sparsity。首先在offline处理时,对weight进行run-length coding,当weight读出时,weight sparsity将被跳过,其对应的activation row也不会从Activation SRAM中读出。这里Activation Channel Addresses Hash Table用于找到与当前weight kernel对应的activation row。个人认为这个idea与前面的feature配合的不是很好。因为既然处理的是帧间残差,我们自然会想到是input activation包含大量的sparsity,但这里确是针对weight sparsity做了优化。

下图展示了本文提出的第三个feature,主要说的是帧间残差矩阵的offchip传输问题。作者设计了一个新的Codec (coder/decoder),将帧间残差根据每个矩阵值的大小分为1/2/4/8b进行传输。1/2/4b的数据进行打包传输,8b的数据由于十分稀疏,所以传输其数据与地址。这其实就是一个经典的优化数据传输的方案,可以理解为dense matrix用结构化数组存储与传输,而sparse matrix采用非结构化数据进行存储与传输的分治策略。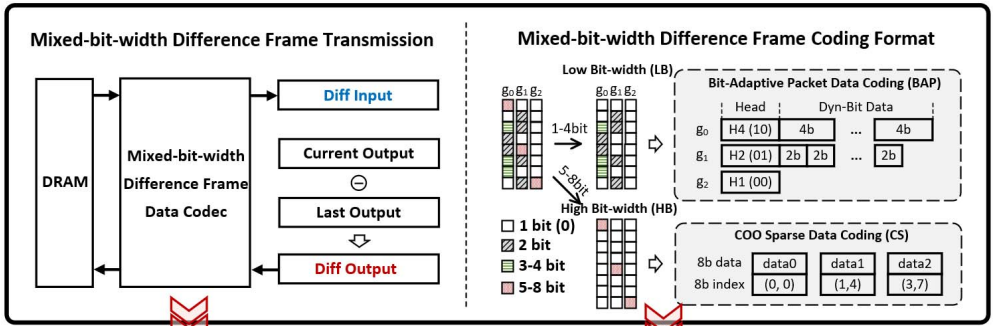
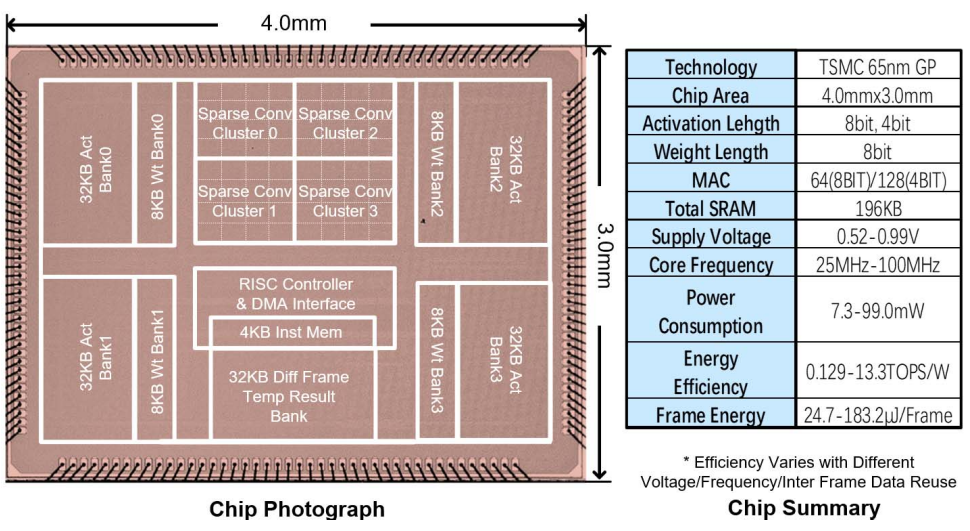
总而言之,该芯片采用65nm制程,芯片大小为$12mm^2$,能降低76.3%的平均功耗并不会产生accuracy loss。在100MHz工作频率,1V的工作电压下,功耗为99mW,吞吐量在85%的weight sparsity ratio(讲道理这个weight sparsity ratio感觉有点高了)以及平均75%的inter frame data reuse的条件下达到了32.8GOPS。