CIMloop——全栈式评估存内计算架构

本文开篇强调了CIM的优势,即拥有更高的density。本文试图对CIM架构进行”full stack modeling”。所谓Full stack(全栈)贯穿了器件,电路,架构,工作负载和数据流各个层面,要对CIM的design space进行建模。
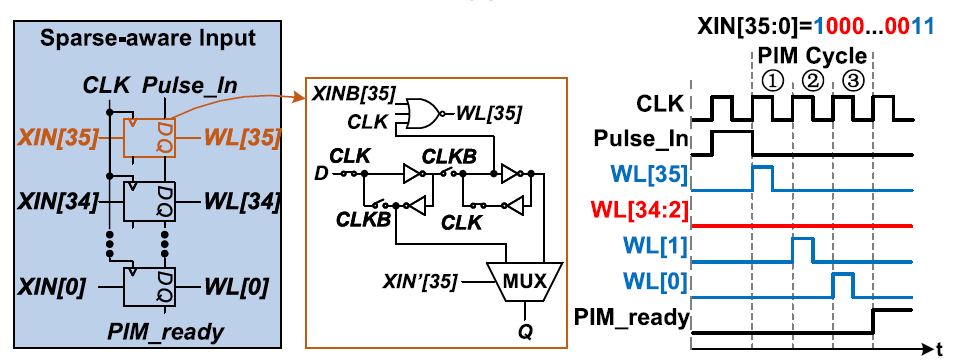
其面临的挑战是:建模必须要有足够的flexibility,不仅要能够描述数据在各种结构之间的移动,举例而言:memory hierarchy中的SRAM可能会互相进行交互。甚至进一步地,其要能描述在电路层面的数据流,比如SRAM内部,数据以怎样的方式读出来进入sense amplifier,之前的建模工具要么缺少足够的flexibility,要么缺少电路层面的建模功能。
为了解决这个问题,建模工具需要描述许多不同的电路架构(比如DRAM与L3/L2/L1缓存)与电路元件(data converters, SRAM bitcells, addressing circuitry)
另一个挑战是,建模工具需要对设计的功耗有一个准确的估计。很多时候,电路的功耗是和输入数据的值有相关性(data-value-dependent),比如一个ReRAM器件的功耗和操作数的大小成正比,这一点在以往的建模工具中并没有得到关注。
总结本文的创新点:
- 提出了一个用于全栈式的描述CIM系统的规范。
- 一个能统一表达各种不同电路与架构的格式
- 一个快速且能准确估计data-value-dependent能耗的模型
文中给出了对最近4个CIM设计的case study。
之所以要进行full stack modeling是出于两个原因:
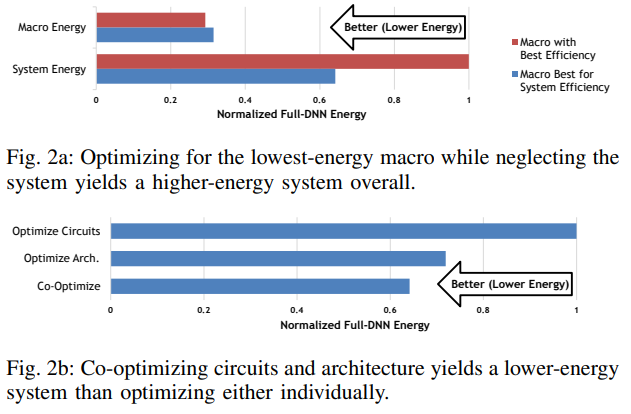
- 优化单独一个层面的设计需要综合考虑其对上下所有层面的影响。比如我们的设计降低了macro层面的功耗,但在系统层面却带来了更多的功耗开销,如下图所示。文中也指出了这个矛盾,能耗上更加优化的macro倾向于降低CIM array的大小,这样能够尽可能的提升utilization rate。但在系统层面,大的CIM array尽管utilization ratio较低,但它能够降低数据在memory hierarchy之间的反复读取,反而节省了更多的能耗。
- 设计时综合考虑所有层面能够帮助设计者找到更好的系统设计方案。
不同的CIM macro采用不同的数据流,一个评估数据流的关键因素是它们能够多大幅度地重用操作数。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 _ConchNest🐚!