
用Butterfly Factorization来加速Transformer运算
用Butterfly Factorization来加速Transformer运算
主要参考论文:
Pixelated Butterfly: Simple and Efficient Sparse Training for Neural Network Models

Learning Fast Algorithms for Linear Transforms Using Butterfly Factorizations

算法原理以及具体的数据流是怎样的?
算法原理在代码上是如何实现的?是否可以将该算法用于所有的矩阵乘法运算?
如果所有的weight都可以用以下两种公式表示,那么activation将怎样和它们进行相乘?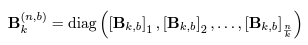
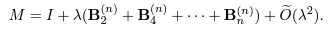
Flat block butterfly与Low-rank两个矩阵各自占多少的计算量?

从这句话可以看到,计算量在二者之间的分配似乎是主观选取的?
该算法的局限性在哪里?
该算法使用一个cost model来评测运算的开销。由于memory coalescing(访问一个单独的memory cell在开销上相当于访问了一整块的memory)的问题,所以一个sparse矩阵中non-zero element的分布也决定了计算这个sparse matrix所需要花费的memory access数目。所以文中提出”exploiting hardware locality is crutial to obtain speed up”。
环境配置
1 | conda create -n fly python=3.8 |
imagenet_preprocess之后
数据集如上图所示,需要在train文件夹内创建一个空文件夹,如class1。
bug1:
解决方案:
将所有的LightningLoggerBase换为pytorch_lightning.loggers.logger.Logger
bug2:
解决方案:
在src.datamodules.imagenet.py中加入以下语句:

bug3:
解决方案:

bug4:
解决方案:
修改configs/experiment/imagenet/mixer/mixers.yaml
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 _ConchNest🐚!