
评测multi-modal task的benchmark
评测multi-modal task的dataset与benchmark
LLaVA images与ALLaVa
LLaVA全称为Large Language and Vision Assistant。LLaVa images包含595K张image-text对。ALLaVa进一步使用高质量的训练数据(high-quality training data)可以在一个轻量化的模型上实现与大型vision-language model(LVLM)近似的表现。他们主要作为LVLM的pretrain训练数据。
MathVista
其全称为Mathematical reasoning benchmark in Visual contexts,其在2024年的ICLR上提出。其目标主要是用于检验multi-modal模型的数学推理能力。其包含6141个样本。
表现最好的模型是GPT-4V,取得了49.9%的平均精度,而人类测试者取得的成绩是65%。
文中列出了数学推理能力对于模型的重要意义,其目标是满足解决教学中的问题、对统计数据进行有逻辑地整理甚至辅助科研等等的需求。
它集中解决5类问题:
- Figure Question Answering (FQA)
- Geometry Problem Solving (GPS)
- Math Word Problem (MWP)
- Textbook Question Answering (TQA)
- Visual Question Answering (VQA)
其中的一些例子为: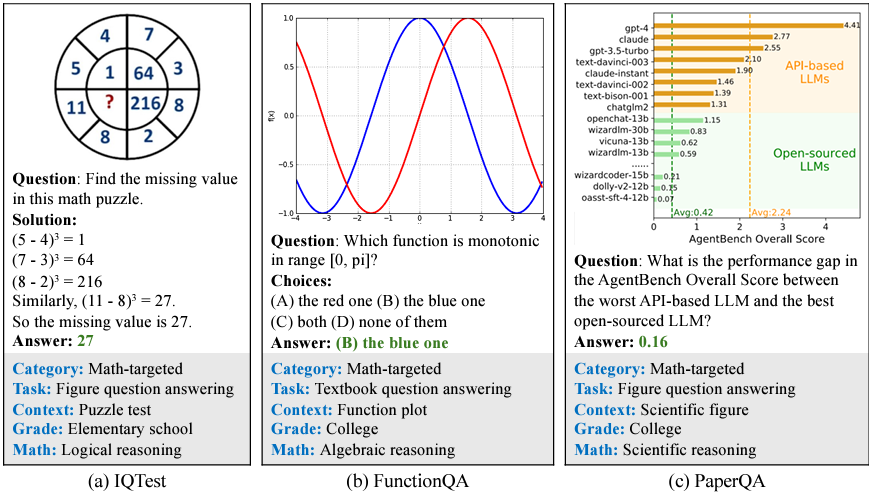
模型的数学推理能力又可细分为以下七个标准,分别是算术推理(ARI),统计推理(STA),代数推理(ALG),几何推理(GEO),数学常识(NUM),科学推理(SCI)以及逻辑推理(LOG)。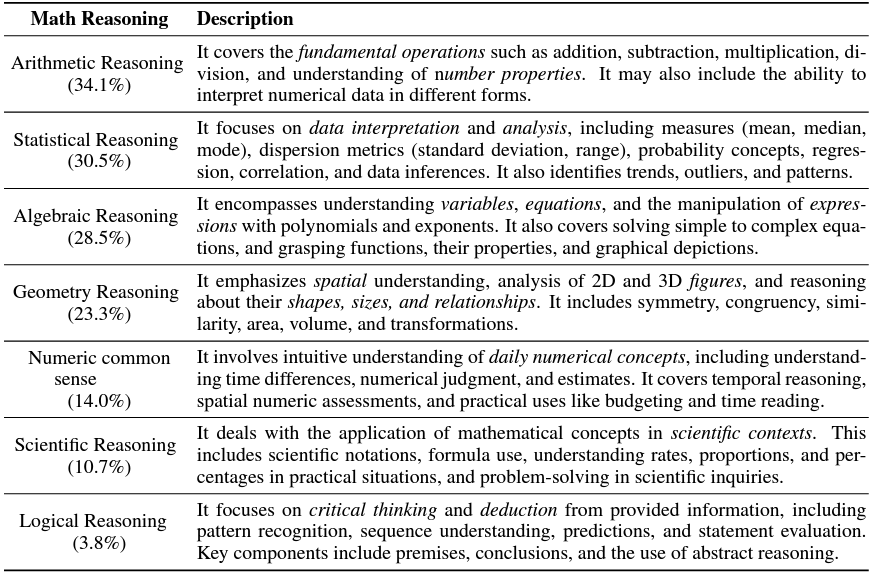
各个模型在该数据集上的表现如下图所示: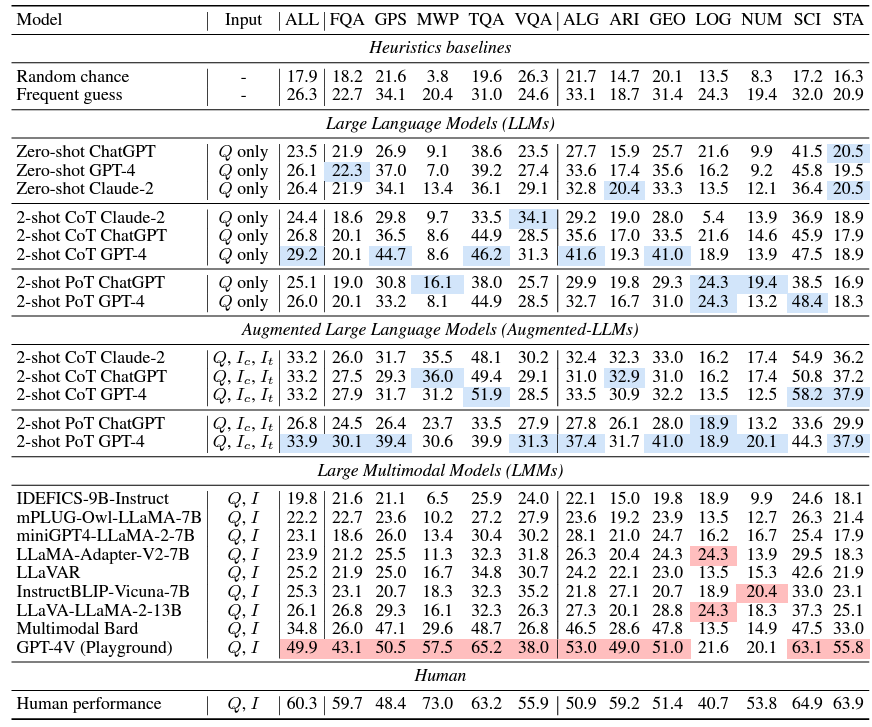
TextVQA
该数据集用于评测模型阅读图片中的文字的能力。其包含28408张包含文字的图片以及45336个针对这些图片设计的问题。下图展示了该数据集的一些例子。

各个模型在该数据集上的表现可以参照下表: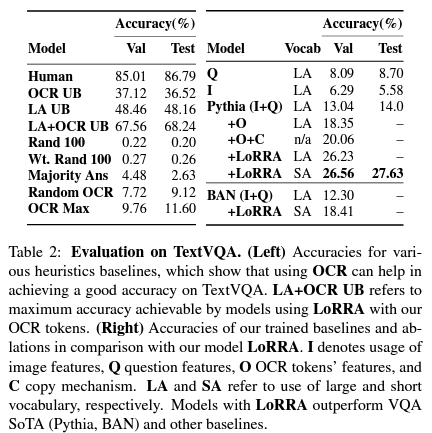
MMB
全称为multi-modality benchmark,其由论文 MMBench: Is Your Multi-modal Model an All-around Player? 提出。其包含3000个多选题,用于从20个不同的角度评测模型的能力。主要评测感知(perception)与推理(reasoning)两个维度的能力,具体的能力评估见下图。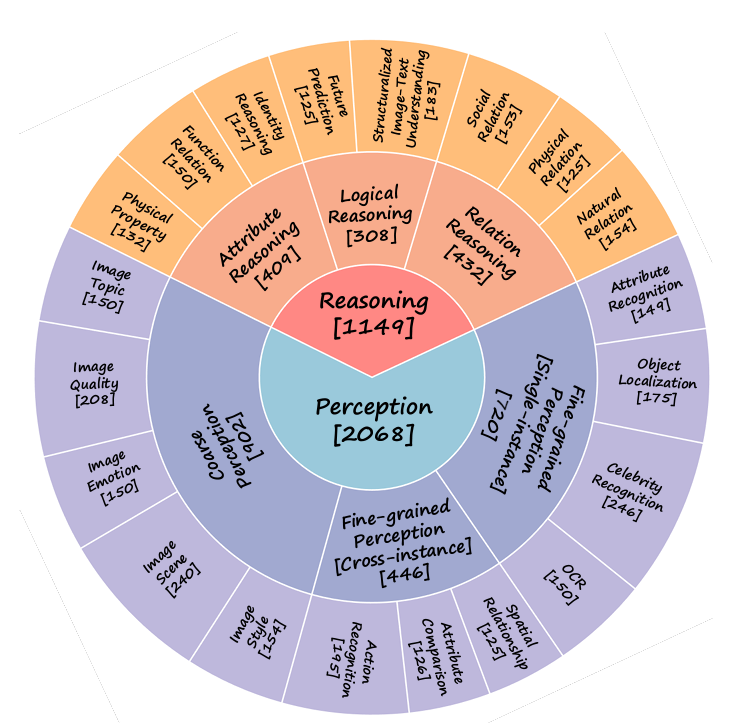
VQAv2
全称为Visual Question Answering,包含265016张图片,每张图片至少由3个问题,每个问题有10个正确的回答以及3个模糊(可能不正确)的回答。
COCO
全称为Common Objects in Context。该数据集包含33万张图片,这些图片主要面向object detection,segmentation与captioning三类任务。