ISSCC2024——C-Transformer怎样解决过高的片外读取问题
ISSCC2024——C-Transformer怎样解决过高的片外读取问题

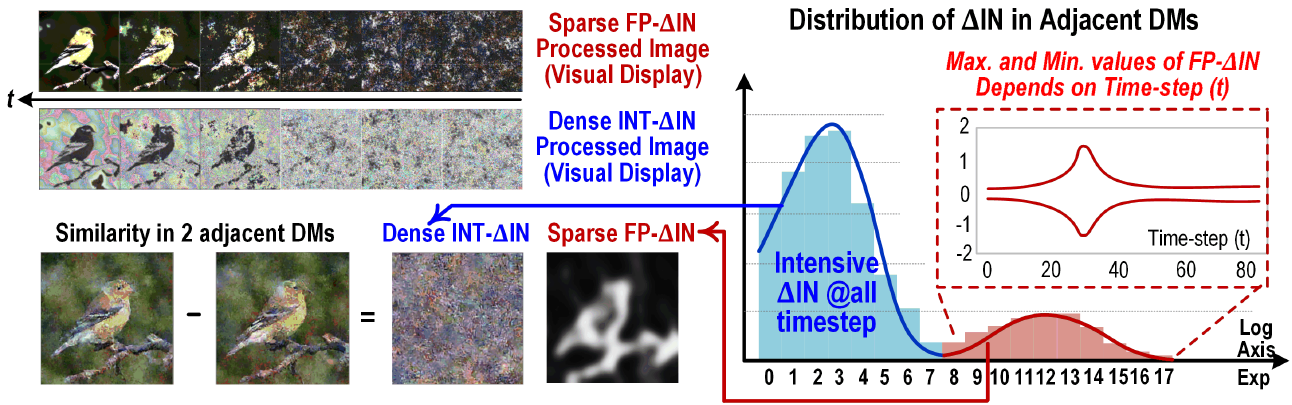
大型语言模型(LLM)的过高的片外读取数目消耗了非常多的系统功耗。本文第一个采取的措施叫Big-little Network。该方法在Transformer网络上的应用详见UC Berkeley的论文 “Big Little Transformer Decoder”
Transformer decoder需要模型反复从片外读入weight矩阵,以及之前生成的tokens的key与value,这导致Transformer decoder的性能被memory bottleneck限制的非常严重。该段论述详见:
下图展示了Big Little Transformer Decoder的工作流程。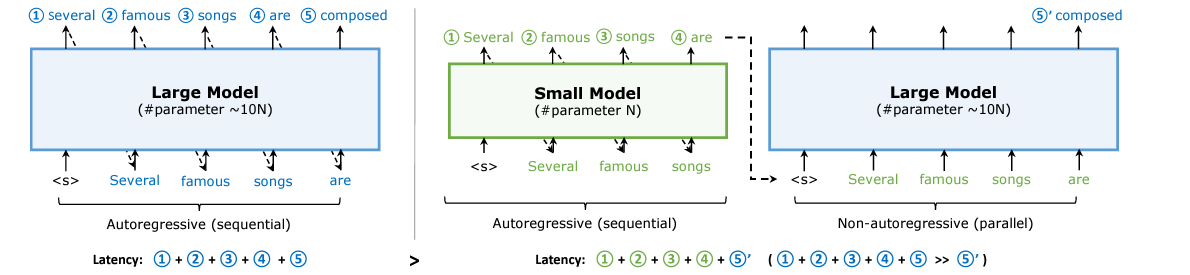
Big Little Decoder包含两个不同大小的模型合作生成文本。小模型会利用fallback policy决定什么时候把workload转到大模型上去。即如果小模型预测出的下一个单词的probability小于一个阈值,那么这个单词将被大模型重新进行预测。同样,大模型会用rollback policy决定什么时候要出来修正小模型的不精确的结果。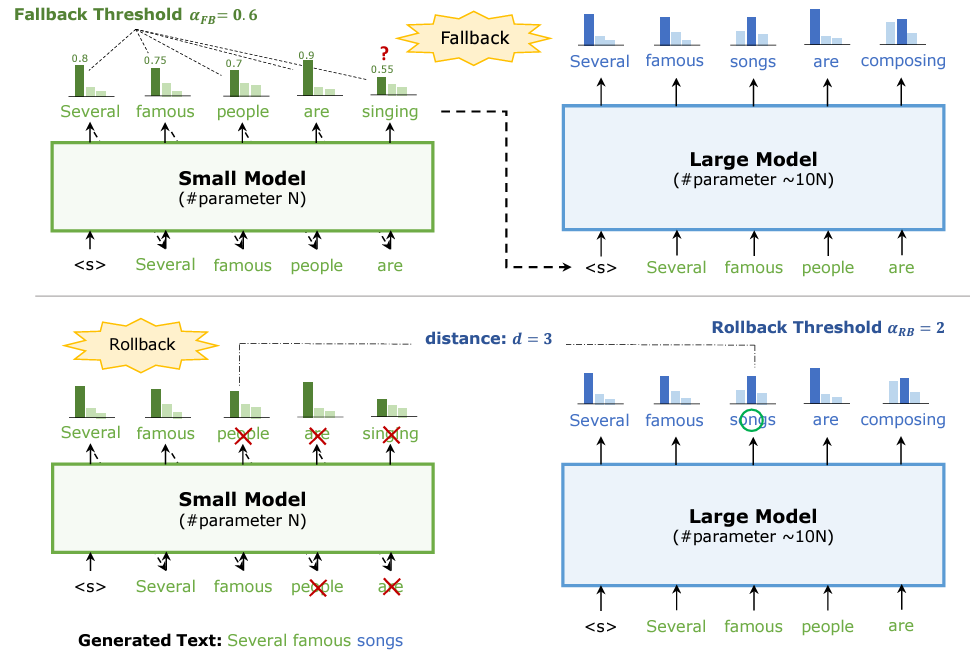
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 _ConchNest🐚!