
计算机体系结构——量化研究方法笔记1
量化设计与分析基础与Memory Hierarchy
体系结构的创新对微处理器性能的提升已经逐渐超过了纯粹依靠工艺节点的改进带来的性能提升。
并行度与并行体系总结
数据级并行 Data-Level Parallelism(DLP)
任务级并行 Task-Level Parallelism(TLP)
计算机设计的量化原理
- 充分利用并行
系统级别并行:如提高在一个典型服务器基准测试(如SPECWeb或TPC-C)上的吞吐量性能,可以使用多个处理器或者多个磁盘。
这也被称作scalability。
指令级别并行:以流水线为例,基本思想就是将指令执行重叠起来。
数字级别并行:组相联(Set Associative)缓存。
- 局域性原理
分为时间局域性和空间局域性。我们可以利用这两个局域性预测代码近期会访问的资源并进行相应的优化。
重点关注Common Case
计算机设计突然关注于优化常见情形。比如处理器钟指令提取以及译码器的使用可能比乘法器频繁的多。Amdahl定律
定义了加速比(speedup),可以表示为:

加速比受限于原计算机中可升级部分所占的比例。
- 处理器性能指标:
每条指令时钟周期数 cycle per instruction (CPI)
指令数 instruction count(IC)
一些谬论和易犯的错误
谬论1:多处理器是万能钥匙
2005年左右之所以会转向一芯多核的设计,原因是因为碰到了ILP (instruction-level-parallelism) wall与power wall。运用几个低时钟频率的核比运用一个高时钟频率的核具有更高的能效。
谬论2:能够提高性能的硬件改进也可以提高能效,至少不会增大能耗
谬论3: 峰值性能能够反映实际观测性能
易犯错误1: Amdahl心碎定律
易犯错误2: 单点故障
易犯错误3: 故障检测会降低可用性
Sun公司的Sun E3000用SRAM来构造L2 Cache,他们部署了奇偶校验但却没有部署ECC纠错码(error correcting code),导致系统虽然检测出了SRAM哪里报错但却没有办法纠正。
什么是ECC纠错码
以Hamming码ECC为例。
比如一个数据为0110101
- 计算redundancy bit的个数
比如,一个7bit数需要有3个bit作为redundancy bit。 - 每个redundancy bit由数据所有bit的子集计算parity得到,比如:

则:p1=1+1+1+0=1
p2=0+1+1+0=0
p3=0+1+1+0=0
3bit的redundancy bit可以理解为数据中各个bit的地址,编码为[p3,p2,p1]。如果p1出错,说明错误存在在地址中最低bit影响的位置,即1,3,5,7,9。这样,用3个bit就可以倒推出错误bit存在的位置。
比如第4个bit存在错误,数据变为0111101
此时:
p1=1+1+1+0=1
p2=0+1+1+0=0
p3=1+1+1+0=1
发现p3出错!此时可倒推得100位置,即第四个bit存在错误。之后只需要把第四个bit翻转即可得到正确的数据。
Hamming法的局限是只能对单个bit error进行纠错,但其硬件结构较为简单。
“Intel Core i7每个时钟周期可以由每个核心生成两次数据存储器引用,i7有4个核心,时钟频率为3.2GHz,除了大约128亿次128位指令引用的峰值指令要求外,每秒最多还可以生成256亿次64位数据存储器引用,总峰值带宽为409.6 GB/s。这一难以置信的高带宽是通过以下方法实现的:实现缓存的多端口和流水线;利用多级缓存,为每个核心使用独立的第一级缓存,有时也使用独立的第二级缓存;在第一级使用独立的指令与数据缓存。与其形成鲜明对比的是, DRAM 主存储器的峰值带宽只有它的6% (25 GB/s)。”
缓存块包含一个tag,指明当前的data block与哪个存储器地址相对应。
组相联 set associative:set是cache中的一组block。首先一个block被映射到一个set上,其可以被放置在这个set中的任一一个位置。要查找一个block,首先由这个块的地址找到对应的set,之后再在这个set内进行并行搜索。如果一个组中有n个block,则缓存的布局称作n路组相联。
四种缓存缺失cache misses情景:
- 强制缺失 Compulsory miss
- 容量缺失 Capacity miss
- 冲突缺失 Conflict miss
- 一致性缺失 Coherency miss
存储器平均访问时间 average memory access time = 命中时间 hit time + 缺失率 miss rate $\times$ 缺失代价 miss penalty
命中时间是指在缓存中命中目标花费的时间,缺失代价是从内存中替代块的时间。
存储器层次结构的36个术语
如果处理器在缓存中找到了所需要的数据项,就说发生了缓存命中。如果处理器没有在缓存中找到所需要的数据项,就是发生了缓存缺失。虚拟存储器意味着一些对象可以驻存在磁盘上。地址空间通常被分为固定大小的块,称为页。在任何时候,每个页要么在主存储器中,要么在磁盘上。当处理器引用一个页中既不在缓存中也不在主存储器中的数据项时,就会发生页错误,并把整个页从磁盘移到主存储器中。由千页错误消耗的时间太长,所以它们由软件处理,处理器不会停顿。在进行磁盘访问时,处理器通常会切换到其他某一任务。从更高级别来看,缓存和主存储器在对引用局域性的依赖性方面、在大小和单个位成本等方面的关系,类似于主存储器与磁盘的相应关系。
今天的绝大多数处理器缓存为直接映射、两路组相联或四路组相联。
处理器是怎样找到缓存中的块的?

块偏移字段从块中选择期望数据,索引字段选择组,通过对比标志字段来判断是否命中。在比较时,核对索引是多余的,存储在第0组的地址,其索引字段必须为0,否则就不能存储在第0组中。
标志(tag)和索引(index)有什么区别?
全相联缓存没有索引字段。因为每一个block都可以存储到缓存中的任一位置,在查找的时候,只需要比较标志位即可找到对应的block。这样做的好处是命中率较高。因为缺少了直接映射的限制,主存中的任意一个位置的block都可以存入缓存。而直接映射的缺陷就是减少了硬件判决,就算要替换也只能替换固定位置的块。而全相联或者组相联的策略,在发生缺失的时候,可以采用多种策略。例如:随机分配,最近最少使用(LRU),先入先出(FIFO)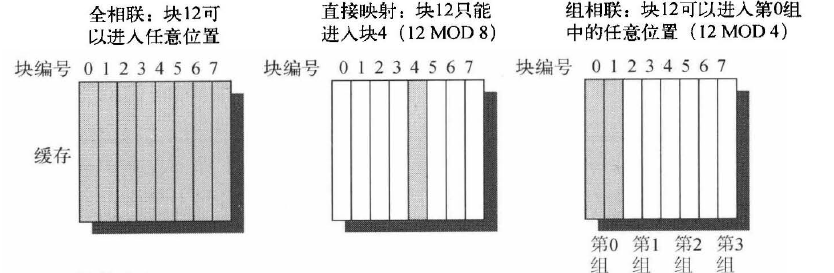
写入策略分为直写和写回。
写回策略的优点:修改后的缓存块仅在被替换时才被写到主存储器。如果,写入的内容立即被应用于后续的计算,则由于则部分内容不会进入存储器,存储器带宽较少,所以该策略对多处理器更具吸引力。一般而言,在多级缓存的架构中,直写策略更适合于高级缓存,而在低级缓存中使用写回策略。
写入缓冲区是用于减少直写期间等待写入操作的过程。
写入分派指在发生写入缺失时将缺失块读到缓存中,随后对其进行写入命中操作。一般写回操作应用的是写入分派策略。直写缓存应用无写入分派策略。
转换旁视缓冲区 Translation Lookaside Buffer (TLB)的作用是什么?
TLB是计算机系统中用于加速虚拟地址到物理地址转换过程的一个硬件组件,是内存管理单元(MMU)中的一个重要组成部分。它的主要作用是减少CPU访问物理内存的次数,从而提高内存访问的效率。TLB的作用包括以下几点:
快速地址转换:当CPU收到来自程序的虚拟内存地址后,首先在TLB中进行寻址。如果TLB中存放着所需的页表,则可以直接将虚拟地址转换为物理地址,避免了访问物理内存中的页表,从而加快了地址转换速度。
减少内存访问次数:引入TLB前,CPU需要至少访问两次物理内存来完成一次虚拟地址到物理地址的转换。引入TLB后,CPU可以在TLB中直接找到所需的页表数据,从而减少了内存访问次数。
提高系统性能:由于TLB的访问速度远快于主存,通过使用TLB,可以显著提高程序的执行效率,尤其是在频繁进行内存访问的应用程序中。
管理页表条目:TLB内部存放的基本单位是页表条目,这些条目对应着RAM中存放的页表条目。TLB的容量虽然有限,但它可以缓存最常访问的页表项,从而提高地址转换的效率。
处理TLB未命中:当TLB中没有对应的存放着所需的页表时,称为TLB未命中(TLB Miss)。在这种情况下,CPU需要访问内存中的页表来获取物理地址,这个过程可能会降低性能。现代处理器通常具备硬件机制来处理TLB未命中的情况,以减少对性能的影响。
支持多级页表和大页:现代处理器的TLB支持多级页表和不同大小的页面,这可以减少TLB条目的数量,提高TLB的效率。
在体系设计中,L1 Cache倾向于使用小而简单的第一级缓存(直接映射或低相联度映射),用以缩短命中时间,并降低功率。
使用路预测技术,在缓存中另外保存了一些位,用于预测下一次缓存访问组中的路或者块,可以有效缩短命中时间。
无阻塞缓存(non-blocking cache)或是无锁定缓存(lockup-free cache)允许在缺失期间继续提供缓存命中,不必因为一次cache miss而停顿。