
Diffusion model on the edge
ACCV2024 G. Kim etc. Diffusion Model Compression for Image-to-Image Translation
提到压缩模型的办法主要可以分为:1. 减少denoising iteration的次数 2. 降低model footprint
这里的model footprint作何解释?
后文提到:
larger models demand larger GPU and more computation during inference, limit deployment on smaller computation platforms, and substantially increase the carbon footprint.
故这里的model footprint主要的意思是模型运行的开销。
CVPR2024: DeepCache
目标:在去噪过程中的每一步中减少模型的大小。之前的work涉及到对模型的重新训练,会让整个压缩过程开销较高。
利用了去噪过程中模型深层特征的相似性,通过缓存(Cache)来避免重新计算网络中的深层特征,仅计算网络的浅层,从而减少计算量。

在U-Net的数据流中,包含一个High-level feature的分支与一个Low-level feature的分支。其中High-level feature的分支被称为main branch,Low-level feature的分支被称为skip branch。main branch将图片通过连续几级的降采样编码为高维的特征图,之后再经过连续几级的升采样还原为低维。而skip branch则直接从降采样过程中产生的Low-level feature直接与升采样过程中产生的feature进行拼接,下图的灰色箭头显示了这一过程。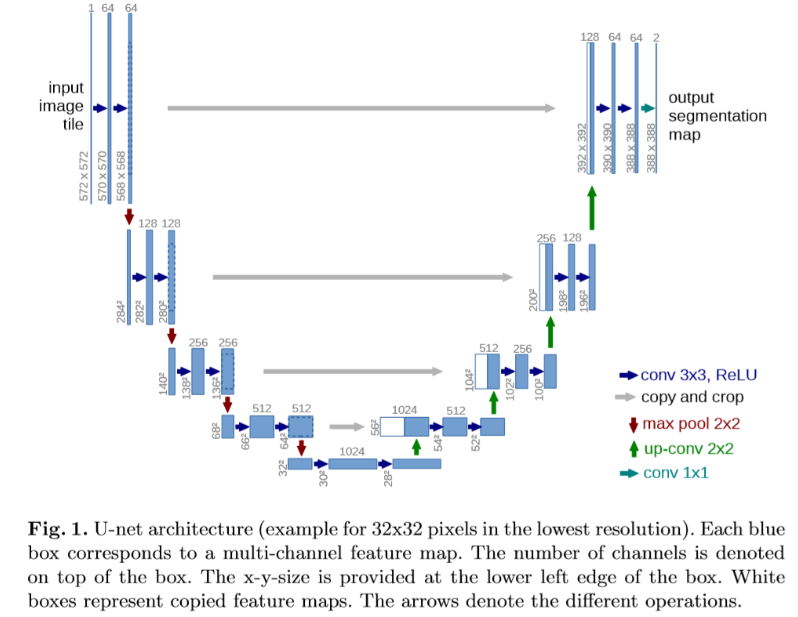
利用特性:
(1)相邻的time step中包含巨大的similarity。
(2)其中的一些time step与相邻的很多time step都有巨大的similarity。

上图展示了DeepCache的过程,其再t-1时刻略去了生成高维特征所需的main branch,仅仅对低维特征进行update。图中的$U_1$特征将会在cache中存储较长的time step。每过N个time step更新一次cache中的$U_1$特征,这被作者称为1:N inference。
对CIFAR-10数据集的生成实验,其将MAC数从6.1G降低到2.63G,FID score从4.16升高到了9.74。
从另一个角度看,DeepCache可以视为在原有$K$步去噪过程中,额外添加了$(N-1)\times K$步的对low-level feature的去噪。作者随后讨论了缓存的feature对于整个diffusion model的重要性。
以生成Cifar10图片的模型为例,如果把缓存的feature map全部替换为0值矩阵,FID从9.74直接攀升到了192.98。而如果保留50个step的full model inference,额外添加的shallow network inference可以使DDIM的FID从4.67降低到4.35。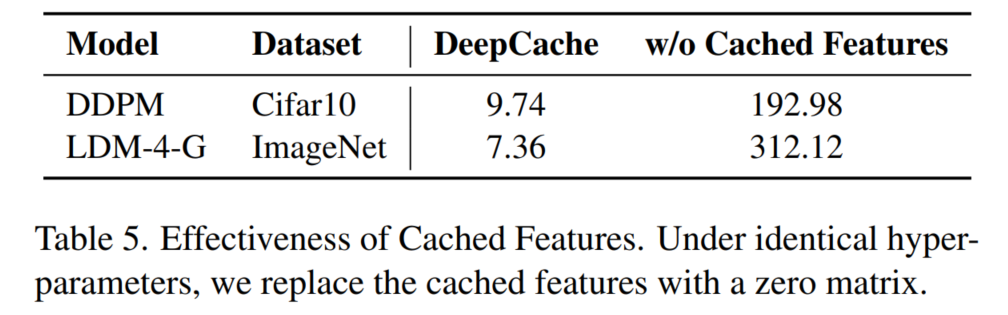
$\bigtriangleup DIT$

NeurIPS 2024: DiTFastAttn
目的:自注意力的二次方复杂性会带来计算挑战。之前的work主要集中在设计注意力机制或网络结构上,虽然可以有效降低计算成本,但是这些方法需要大量的再训练成本。训练DiT需要大量的数据和计算,因此需要post-training compression方法。
训练后压缩:
DiT推理过程中注意力计算的三个关键冗余:
Spatial Redundancy,许多注意力头专注于局部信息;
Temporal Redundancy,相邻步骤的注意力输出之间具有高度相似性;
Conditional Redundancy, 条件和无条件inference具有显著相似性。(在前向传播过程中,CFG会进行两次前向传播,一次是使用条件输入的推理,一次是不使用条件输入的推理)
为了解决这些冗余提出了三种技术:
- 带有残差缓存的窗口注意力,来减少空间冗余;在第一个步骤中缓存完整的注意力和window attention输出之间的残差,在后续的几个steps中重用该残差。
- 跨时间步的注意力共享,来利用步骤之间的相似性;
- 跨CFG(classifie-free guidance)进行注意力共享,来跳过条件生成期间的冗余计算。

DiTFastAttn提供了一种独立于使用特定的量化位宽、调度程序和时间步长的补充解决方案。
不同层在不同时间步长具有不同的冗余度:每个步骤的每一层应用哪些技术很重要。
作者使用的是贪婪算法,来看在哪里使用什么技术。
对于DiT模型,AST和ASC在早期的时间步中使用,完全注意力主要出现在初始注意力层中。